

近日,我院常姗教授课题组在去中心化联邦学习领域取得重要进展。相关研究成果《ProtoGenesis: Prototype Training with Zero Local Samples for Heterogeneous Clients in Fully Decentralized Federated Systems》被分布式系统领域国际顶级会议IEEE ICDCS 2026正式接收录用。
随着边缘设备产生的数据快速增长,联邦学习逐渐成为打破数据孤岛、满足隐私与监管约束的重要计算范式。然而,在实际部署中,客户端通常同时面临数据异构和系统异构问题:异构的客户端数据导致本地模型难以学习全局完整类别分布,尤其对本地缺失类别的泛化能力较弱;异构的系统则导致统一模型部署和同步训练效率低下,并容易受到计算资源、网络带宽和动态连接状态的限制。现有异构联邦学习方法虽然能够缓解模型结构不一致带来的协同训练问题,但往往更关注提升客户端模型在本地已有类别上的性能,对缺失类别的识别能力不足。同时,许多方法仍假设客户端具有相对稳定且充足的资源,较少考虑真实边缘环境中客户端物理分布分散、点对点通信链路动态变化(如图1所示)。
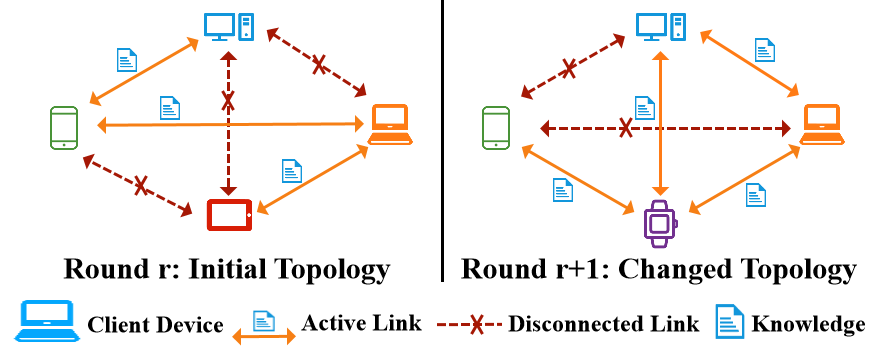
图 1 随时间变化的通信拓扑
针对上述问题,课题组提出了面向异构去中心化联邦学习的ProtoGenesis框架。该方法结合语义保持自编码器与原型协同训练机制,通过交换低维语义嵌入,为客户端重构本地缺失类别的辅助样本,从而缓解异构数据场景下未见类别识别能力不足的问题;同时,ProtoGenesis 将客户端计算能力与训练时间约束纳入模型选择过程,自适应匹配不同复杂度的本地模型;进一步通过类别原型交换与聚合,引导模型学习稳定的类级表征,从而在提升未见类别泛化能力的同时降低通信开销。
在实验评估方面,课题组基于Nvidia Jetson 设备搭建了真实物理验证系统(如图2所示),并针对通信延迟开展了详尽的测试。

图2 基于Nvidia Jetson的系统
实验结果显示,ProtoGenesis在数据高度异构的情况下,客户端个性化模型平均精度随通信轮数增加而展现出稳健的上升趋势,最终性能显著优于目前先进的联邦学习算法(如图3所示)。
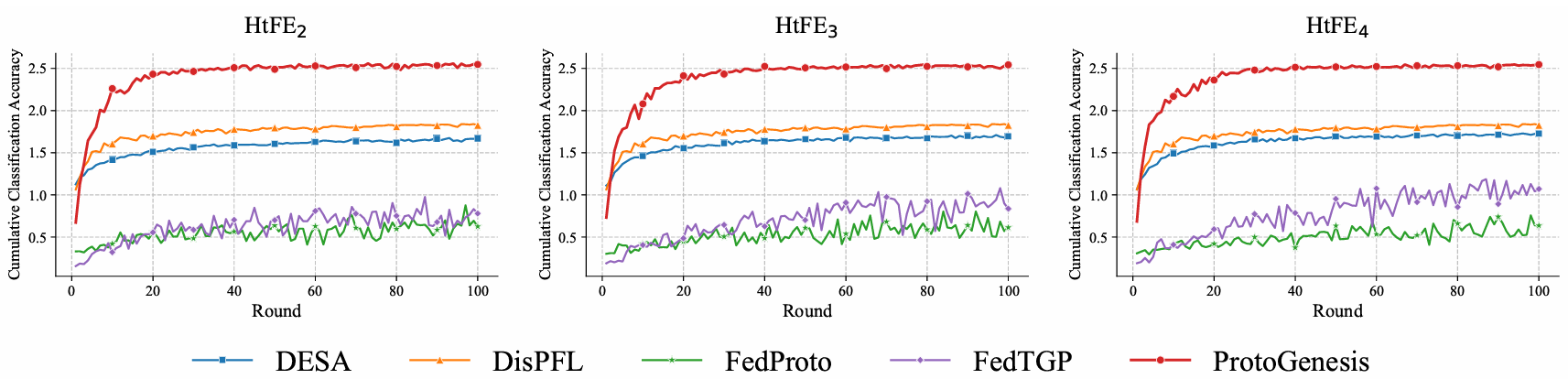
图3 模型精度随通信轮数的变化情况
该成果体现了团队在去中心化联邦学习方向的持续积累与创新能力,为未来资源受限、高异构且高动态的边缘智能系统提供了无感协同训练技术路径。
IEEE International Conference on Distributed Computing Systems (ICDCS)是IEEE Computer Society 旗下分布式计算与系统领域的旗舰会议之一,在中国计算机学会(CCF)推荐的国际学术会议目录中被列为B类(CCF-B)。该会议长期聚焦分布式系统架构、边缘与云计算、分布式人工智能及安全隐私等核心与新兴方向,审稿标准严格、竞争激烈,论文接收率常年保持在18%至20%。